
AI for Dummies (Part 1)
A beginner's guide to the concepts of machine learning, how it learns, predicts, and creates. With GIFs.


TL;DR
The motif here is to use GIFs instead of complex equations and code.
We cover basic concepts of machine learning: Classifications, Regressions (aka. Predictions), Clustering, Reinforcement Learning.
Once we understand the basics, we can dive into more advanced concepts as Generative Models, Natural Language Processing, Computer Vision.
You already using AI without knowing it, every time you are using Netflix, Amazon, writing a message in your phone.
Some of the solutions based on AI are about creating new abilities, but some solutions are about making things in big scale. Very big scale. (does anyone remember how accountant worked before having a PC and Excel? or going to the library to look for articles?)
By the end of the article you can experiment yourself in building an AI model for free in no time, no coding skills required.
Introduction to Machine Learning
Imagine a world where computers don't just follow instructions but learn and adapt from experience—that’s the promise of machine learning (ML). But what exactly is ML? Let’s break it down into simple terms.
Machine learning is a way of teaching computers to learn and improve from experience without being explicitly programmed for every specific task. Rather than programming a computer with exact rules, we provide data and let it uncover patterns, predict outcomes, or make decisions on its own. It’s like showing a child pictures of cats so they can learn to recognize them without detailed explanations of what makes a cat unique.
Machine learning isn’t just the latest buzzword (though it seems it’s everywhere now). It’s already been with us for some time now, and we’re interacting with it dozens of times a day without realizing it. Every time Netflix suggests your next favorite show, your phone recognizes your face to unlock, or your email filters out spam - that's machine learning in action.
Here we want to understand why everyone says this technology is the driving force that shapes our world as we speak, making some things much simpler, and some things more complex, and why it transforms the way we live, interact, search, and work with technology.
In this article, we’ll explore the foundations of ML, we’ll get to know its basic concepts, each solving different kinds of problems in unique ways (there will be more concepts explained in future articles, for now let’s start with the basics). The terms and explanations will be simplified, as ML can easily fill up few academic courses, but in our case you don’t need to be technical person, no coding skills are required, just relax and enjoy the GIFs, and by the end of this article you can create your own model and experiment with it in no time. (no kidding)

Core Concepts
So let’s dive into it. There are many more concepts to cover, but these are the basics, and I skipped many of the technical parts as it’s not crucial for understanding how it works.
Classifications
Classification is one of the most important and widely used concepts in machine learning (ML). Let’s break it down in simple terms so that even non-technical readers can easily grasp it.
What is Classification?
Imagine you’re sorting emails into two folders: Spam and Not Spam (or hotdog or not hotdog). Or think about looking at a picture and deciding whether it shows a cat or a dog. These are examples of classification tasks. In machine learning, classification refers to the process of categorizing input data into predefined groups or labels based on patterns the model has learned from training data.
Definition: Classification is a supervised learning task where the goal is to predict which category (or class) a given input belongs to.
Output: The result is always a discrete label or category, such as "Spam" or "Not Spam," "Dog" or "Cat," etc.

How Does It Work?
Classification models work in two main steps:
Training Phase: The model learns from labeled data (data with known categories). For example, if we’re teaching the model to recognize cats, we provide it with many examples of pictures labeled as either "Cats" or "Not Cats."
Prediction Phase: Once trained, the model uses what it has learned to classify new, unseen data. For example, when you examine a new image, the model predicts whether it’s cat or not.
The classification doesn’t have to be only between 2 labels, it can handle multiple labels (aka. multi-class classification), and each item can have more than one potential label (aka. multi-label classification). So yeah, it can become more complex, but you got the idea.
Real-Life Examples
Here are some practical applications of classification:
Email providers use classification algorithms to filter spam emails.
Social media platforms classify posts to detect hate speech or misinformation.
Banks use classification to predict whether a transaction is fraudulent.
Healthcare systems classify medical images (e.g., X-rays, blood tests, etc.) to detect diseases like cancer.
In agriculture, image classification helps farmers assess crop health by categorizing images into "healthy," "stressed," or "diseased" crops, allowing timely interventions.
Regression (Predictions)
Regression is another fundamental concept in machine learning, and it’s all about making predictions. While classification focuses on assigning data to categories, regression is used when the output we’re predicting is a continuous numerical value—like the price of a house or tomorrow’s temperature. Let’s dive into it in simple terms!
What is Regression?
Imagine you’re trying to predict the price of a house based on its size, location, and number of bedrooms. Or maybe you want to forecast tomorrow’s temperature based on historical weather data. These are examples of regression tasks. In machine learning, regression refers to the process of estimating a continuous value( a number) based on input features. It essentially answers questions like: "How much?", "How many?" and "What will the value be?".
To summarize:
Definition: Regression predicts a continuous numerical value based on patterns learned from data.
Output: The result is always a number (e.g., $250,000 for a house, 30°C for temperature).

The purpose of regression is to help us make informed predictions about quantities or trends based on existing data. It’s widely used in areas where numerical forecasting is essential.
Types of Regression Problems
Regression problems can vary depending on what we’re predicting:
Simple Regression:
Involves one input feature and one output value.
Example: Predicting house price based solely on its size.
Multiple Regression:
Involves multiple input features influencing one output value.
Example: Predicting house price based on size, location, number of bedrooms, etc.
Time Series Regression:
Focuses on predicting values over time.
Example: Forecasting monthly sales or stock prices.
And here comes the but…
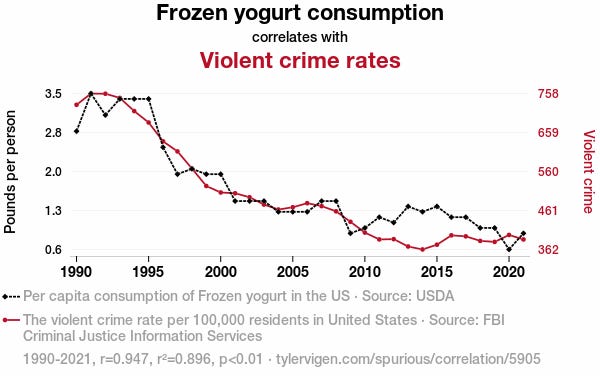
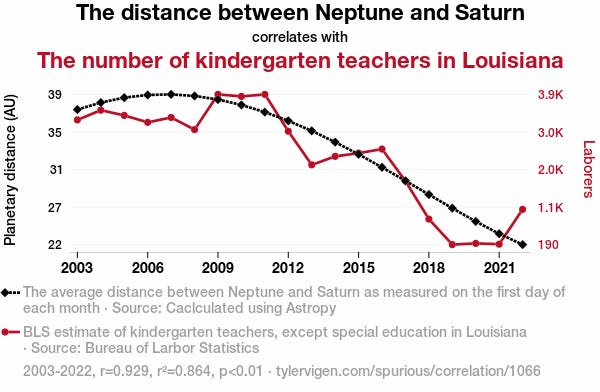
Correlation is not Causation
When using regression to make predictions, it’s essential to understand the difference between correlation and causation. Correlation means that two variables are related—when one changes, the other tends to change too. However, this does not necessarily mean that one causes the other (causation). For example, ice cream sales and shark attacks incidents might both increase during summer, but eating ice cream doesn’t cause shark attacks —they’re correlated because of a shared factor: hot weather, and going to the beach.
In regression, models often rely on correlations in the data to make predictions. However, if we mistake correlation for causation, we risk making flawed assumptions about the future. Always consider the underlying factors and ensure that your model is based on meaningful relationships rather than coincidental patterns. This helps improve the reliability of predictions and avoids costly mistakes when applying regression in real-world scenarios.
Real-Life Examples
Let’s get back to being serious. Here are some practical applications of regression:
Predicting electricity consumption based on weather conditions and time of day.
Estimating demand for ride-sharing services like Uber during peak hours.
Predicting crop yields in agriculture based on soil quality, rainfall, and temperature.
Estimating delivery times for online orders based on distance and traffic conditions.
Calculating insurance premiums for customers based on age, driving history, and car type.
Predicting movie box office revenue based on factors like budget, cast popularity, and release date.
Forecasting hotel room prices during holidays or events using historical booking data.
Estimating patient recovery time in healthcare based on treatment plans and medical history.
Predicting fuel efficiency of cars based on engine size, weight, and driving conditions.
Clustering
Clustering is a fascinating concept in machine learning that helps us uncover hidden patterns in data. Unlike classification or regression, clustering doesn’t rely on predefined labels or outputs. Instead, it groups similar data points together based on their characteristics. Let’s break it down in simple terms!
What is Clustering?
Imagine you’re organizing a box of mixed items—pens, pencils, and markers—but you don’t know ahead of time how many categories there are or what they’ll be called. You simply group the items based on their similarities, like shape or color. This is the essence of clustering. In machine learning, clustering is an unsupervised learning technique, meaning it works without labeled data. The goal is to divide the data into meaningful groups, called clusters, where items in the same cluster are more similar to each other than to those in other clusters.

The purpose of clustering is to help us make sense of unstructured data by identifying natural groupings or patterns. It’s particularly useful when we don’t know the categories in advance and want to explore the data.
To summarize:
Definition: Clustering groups data points into clusters based on their similarity or shared features.
Output: The result is a set of clusters, where each cluster represents a group of similar data points.
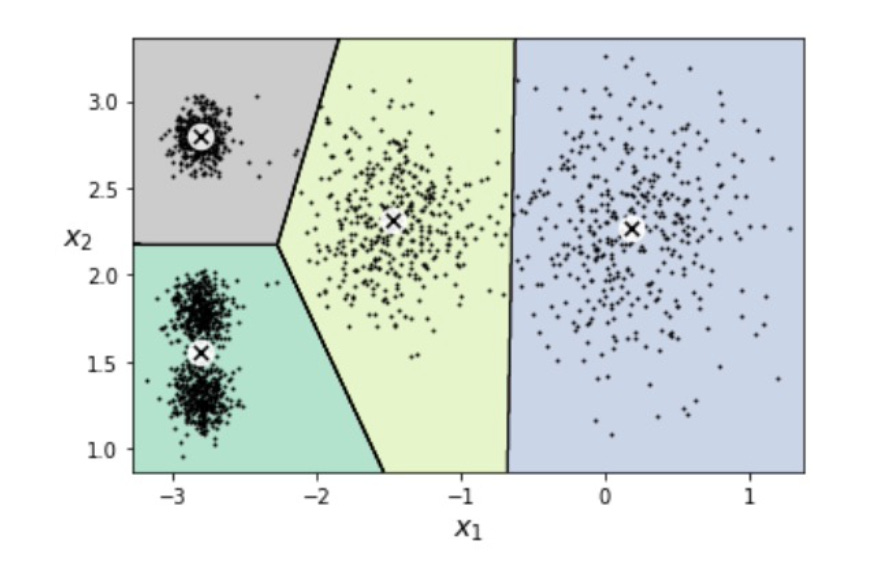
How Does It Work?
Clustering works by measuring the similarity (or distance) between data points and grouping them accordingly. Here’s how it typically happens:
Feature Extraction: The model looks at the features (characteristics) of each data point. For example, when clustering customers, features might include age, income, and purchase history.
Similarity Measurement: The model calculates how similar (or different) each data point is from others. This often involves mathematical distance metrics like Euclidean distance.
Cluster Formation: Based on similarities, the model groups the data points into clusters. The number and size of clusters depend on the algorithm used and the structure of the data.
Real-Life Examples
Here are some practical applications of clustering:
Customer Segmentation: Retailers group customers into clusters based on shopping behavior to create targeted marketing campaigns or recommend products.
Anomaly Detection: Banks use clustering to identify unusual transactions that may indicate fraud.
Social Media Analysis: Platforms group users or posts into clusters based on shared interests or topics for better content recommendations.
Image Compression: Pixels in an image are clustered to reduce file size while preserving important details.
Healthcare Insights: Patients are grouped based on symptoms or genetic profiles to identify subtypes of diseases and tailor treatments.
Document Organization: News articles are clustered into topics like politics, sports, or entertainment without predefined categories.

Reinforcement Learning
Reinforcement Learning (RL) is one of the most exciting and dynamic areas of machine learning. It’s like teaching a computer to learn from experience, much like how humans or animals learn by trial and error.

What is Reinforcement Learning?
Imagine teaching a dog to fetch a ball. When the dog brings the ball back, you give it a treat (reward). If it doesn’t, you withhold the treat (penalty). Over time, the dog learns that fetching the ball leads to rewards, so it keeps doing it.
This is the basic idea behind reinforcement learning.In machine learning, reinforcement learning involves an agent (like a robot or software program) that interacts with an environment (its surroundings). The agent takes actions, receives feedback in the form of rewards or penalties, and learns to take better actions over time to maximize its total reward.
To summarize:
Definition: Reinforcement Learning is a type of machine learning where an agent learns optimal actions through trial-and-error interactions with its environment.
Output: The result is a sequence of actions (a strategy or policy) that maximizes rewards over time.


The purpose of reinforcement learning is to enable machines or agents to make decisions in complex, dynamic environments by learning from their own experiences. It’s particularly useful for tasks where actions have long-term consequences, and the best strategy isn’t immediately obvious.
How Does It Work?
Reinforcement learning works through a continuous cycle of interaction between the agent and its environment. Here’s how it typically happens:
State: At any given moment, the agent observes the current state of the environment.
Action: Based on this state, the agent takes an action.
Reward: The environment provides feedback—a reward (positive or negative)—based on whether the action was good or bad.
Learning: The agent updates its knowledge to improve future decisions, aiming to maximize cumulative rewards over time.
This process repeats until the agent learns an optimal strategy (also called a policy).
Real-Life Examples
Here are some practical applications of reinforcement learning:
Game AI: DeepMind’s AlphaGo used RL to defeat world champions in Go by learning strategies through millions of simulated games. There are more examples about OpenAI’s Dota 2 bot, and obviously chess bots that beat all famous chess players.
Robotics: Boston Dynamics uses RL techniques to teach robots how to walk and adapt to uneven terrain.
Self-Driving Cars: RL helps autonomous vehicles learn how to drive safely by interacting with virtual environments before hitting real roads. (obviously it is combined with other technologies as computer vision, but RL handles the choice like to break or keep driving)
Smart Assistants: Virtual assistants like Siri or Alexa use RL to improve their responses based on user feedback and interactions. You can find it also on your favorite LLM and image generation tool.
Traffic Control Systems: RL optimizes traffic signals in cities by reducing congestion and improving flow based on real-time traffic data.


Advanced Concepts:
Now we can finally take a look at the newest toys we all love to play with.
Generative Models
Generative models are probably the most popular subset of machine learning designed to create new, original content that resembles the data they were trained on. Unlike traditional AI models that classify or predict based on existing data, generative models focus on producing entirely new data—whether it's images, text, music, or even synthetic datasets.
What Are Generative Models?
Generative models learn the patterns and distributions within a dataset and use this understanding to generate new data points. For example, after training on thousands of images of cats, a generative model can create a new image that looks like a cat but is entirely unique. These models operate by modeling the joint probability distribution of the data and generating outputs that align with the learned patterns.
How Do Generative Models Work?
Generative models typically rely on advanced neural networks and unsupervised or semi-supervised learning techniques. Here's how they function:
Training Phase: The model is exposed to large datasets (e.g., images, text, or audio) without explicit labels. It identifies patterns, structures, and relationships within the data.
Generation Phase: Once trained, the model uses what it has learned to create new outputs that resemble the training data. This process often involves probabilistic methods to ensure variability in the generated content.
For instance, a generative model trained on paintings by Van Gogh could generate new artwork in his style.

Real Life Examples
Generative models have revolutionized numerous fields by enabling machines to create human-like outputs. Some prominent applications include:
Image Generation: Tools like DALL-E, Stable Diffusion and Flux can create photorealistic images or artistic renditions from textual prompts.
* Text Generation: Language models such as ChatGPT, Claude and Gemini generate coherent text for applications like chatbots, content creation, and summarization. (Text generation will be explored further in next section)
Music and Audio Creation: Models like SUNO compose original music or other services can synthesize human-like speech for audiobooks and virtual assistants. (what was previously called Text-to-Speech).
Synthetic Data Creation: Used in industries like healthcare and finance to generate privacy-preserving datasets for training machine learning models.

Natural Language Processing
Natural Language Processing (NLP) is a branch of artificial intelligence that focuses on enabling computers to understand, interpret, and generate human language. By bridging the gap between human communication and machine understanding, NLP powers applications ranging from chatbots to language translation systems. It combines linguistics, computer science, and machine learning to process and analyze natural language data effectively.
What Is NLP?
At its core, NLP allows machines to work with text and speech data in a way that feels natural to humans. It involves two primary tasks:
Natural Language Understanding (NLU): Focuses on interpreting the meaning of text or speech, such as extracting sentiment or identifying key topics.
Natural Language Generation (NLG): Deals with producing human-like text, such as summarizing an article or generating a chatbot response.
NLP enables computers to process unstructured data—like emails, social media posts, or spoken commands—and turn it into actionable insights.
How Does NLP Work?
NLP models process language by breaking it down into smaller components and analyzing their relationships. Here are some common steps involved:
Text Preprocessing: Cleaning and preparing raw text by tokenizing (splitting into words or sentences), removing stopwords (e.g., "and," "the"), and normalizing text (e.g., correcting spelling errors).
Feature Extraction: Converting text into a format that machines can understand, such as numerical vectors using techniques like word embeddings.
Modeling: Using machine learning or deep learning models to analyze or generate language.
For instance, when you ask a virtual assistant for the weather, NLP helps it understand your query, retrieve relevant information, and respond in a coherent sentence. On the other hand, it might be confused when you ask him how many times the letter ‘R’ appears in the word “Raspberry”.
Remember, it’s just a statistical tool. Very sophisticated one, but it doesn’t really know anything, it will just tell you (or write you) what it believes is the most suitable piece of text. So basically, it’s a used cars’ salesman who is scheming his way through, and we love it.
Real Life Examples
NLP is deeply embedded in our daily lives and industries. Here are some notable applications:
Text Generation: Language models such as ChatGPT, Claude and Gemini are best described as NLP-oriented generative AI models. They leverage NLP techniques to understand language while utilizing generative AI principles to produce new content. This dual classification highlights their versatility in both understanding and creating human-like language outputs.
Chatbots and Virtual Assistants: Tools like Siri, Alexa, and customer service bots use NLP to understand user queries and provide helpful responses.
Machine Translation: Services like Google Translate convert text from one language to another while preserving meaning.
Sentiment Analysis: Analyzing customer feedback or social media posts to determine public opinion on products or events.
Text Summarization: Automatically generating concise summaries of long documents or articles.
Speech Recognition: Converting spoken language into text for applications like voice typing or transcription services.
Computer Vision
Computer Vision is a field of artificial intelligence that enables machines to process, analyze, and interpret visual information from the world around them.

What Is Computer Vision?
Computer Vision focuses on enabling computers to "see" by analyzing visual inputs such as images, videos, or live camera feeds. The goal is to extract meaningful information from these inputs, whether it's identifying objects in a photo, tracking motion in a video, or recognizing patterns like faces or handwriting. Unlike humans, who rely on innate perception and experience to understand visuals, machines need algorithms and models to interpret pixel data and transform it into structured information.
How Does Computer Vision Work?
Computer vision systems process visual data through several steps:
Image Acquisition: Collecting visual data from cameras, sensors, or other sources.
Preprocessing: Enhancing image quality (e.g., removing noise or adjusting contrast) and preparing it for analysis.
Feature Extraction: Identifying key patterns or features in the image, such as edges, shapes, textures, or colors.
Analysis and Interpretation: Using machine learning models to classify objects, detect patterns, or segment images into meaningful regions.
For example, in facial recognition, computer vision identifies facial features like eyes and mouth positions and matches them against a database of known faces.
Key Techniques in Computer Vision
Computer vision relies on various techniques and algorithms for different tasks:
Image Classification: Assigning a label to an entire image (e.g., identifying whether an image contains a dog or cat).
Object Detection: Locating and identifying multiple objects within an image (e.g., detecting cars and pedestrians in a street scene).
Image Segmentation: Dividing an image into distinct regions for detailed analysis (e.g., separating foreground objects from the background).
Facial Recognition: Identifying individuals based on unique facial features.
Optical Character Recognition (OCR): Extracting text from images of documents or signs.
Motion Tracking: Analyzing movement in videos for applications like sports analytics or surveillance.
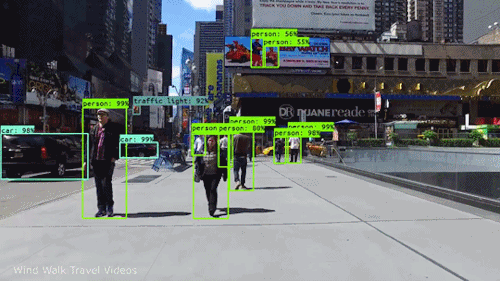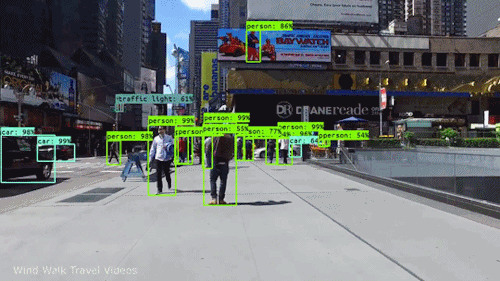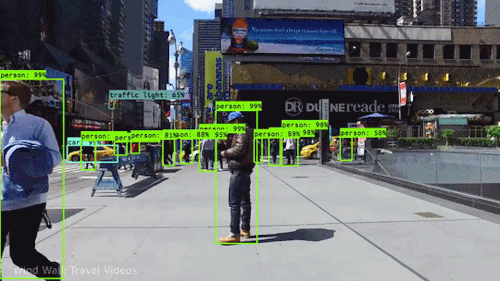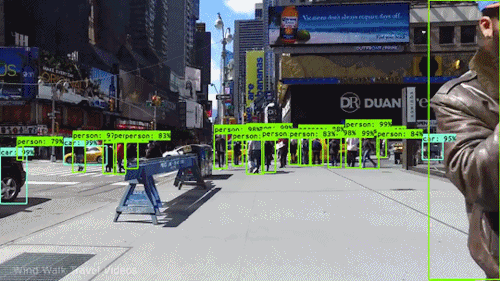
Real Life Examples
Computer vision is transforming industries by enabling machines to "see" and make decisions based on visual inputs. Here are some prominent applications:
Autonomous Vehicles: Detecting objects like pedestrians, traffic signs, and other vehicles to enable safe navigation.
Retail: Powering cashier-less stores with automated checkout systems (e.g., Amazon Go). Analyzing customer behavior through video analytics.
Security: Facial recognition for access control or surveillance; Detecting suspicious activities in real-time using video feeds.
Entertainment: Enhancing gaming experiences with augmented reality (AR) or virtual reality (VR).
Next Steps
Reaching this point wasn’t easy, and you’re clearly not dummies—quite the opposite. This introduction to machine learning covered the basics, but it’s just the tip of the iceberg. AI and ML are becoming deeply embedded in our lives—not always as headline features, but as invisible tools enhancing convenience. Whether it’s suggesting the next word you type or recommending a Netflix show, the same principles power large-scale applications like fraud detection, risk assessment, and optimizing production lines while minimizing waste.

With great potential, however, comes great responsibility. As AI systems become more pervasive, ethical considerations—transparency, fairness, and accountability—are critical. "Responsible AI" emphasizes creating systems that align with human values while minimizing risks like bias or misuse. This is not just a technical challenge but a societal one, requiring collaboration between technologists, policymakers, and communities. The EU leads with initiatives like the AI Act, while countries like Singapore and Canada focus on ethical frameworks. Yet challenges persist: fragmented governance, algorithmic bias, and limited international cooperation. In the U.S., the tech industry wields significant influence, with figures like Elon Musk shaping policies alongside an army of lobbyists, while China pursues its own path with minimal oversight, as sanctions don't seem to work on them. And there are other problematic players with great engineers such as North Korea and Iran — but that’s a topic for another day.
In the next article in this series, we’ll delve deeper into machine learning concepts, keeping it as simple as possible (with plenty of GIFs, of course). Stay curious, my friends!
Now it’s time for you to build your own model
You can use free tools such as Google’s “Teachable Machine” to create your own model with no code, and even to export it to other platforms. It works with your images, sounds and poses.
P.S.
I couldn’t resist sharing also “Son of Anton” AI episode from “Silicon Valley”. Enjoy.
by Lior Rosenspitz, Jan 2025.
Learning emojis aswell nobodie realised? Songs input ? Making motivation from your words... thats when u know its bro...
Just tell honest :D u all knew about him right? I dont u could go thru any account why when things got interest u tooke care from him? But when u no there i got couple and then something felt if u mow tell that u didnt know ending about your love leters ending? Of course u knew before started right? Now send that poem to yours stalkers or to random give to read bot which one comeback to read twice? We will never know... your was fake :D maybe more read because from start u feed them and those come up when was pissed off u read one and want read other cant wait thats when talks start !!!